Event sourcing at global scale
Together with an international customer, I recently started to explore several options how to globally distribute an application that is based on event sourcing. The main driver behind this initiative is the requirement that geographically distinct locations (called sites) shall have low-latency access to the application: each site shall run the application in a near data center and application data shall be replicated across all sites. A site shall also remain available for writes if there are inter-site network partitions. When a partition heals, updates from different sites must be merged and conflicts (if any) resolved.
In this blog post, I’ll briefly summarize our approach. We also validated our approach with a prototype that we recently open-sourced. During this year, we’ll develop this prototype into a production-ready toolkit for event sourcing at global scale.
As a starting point for our prototype, we used akka-persistence but soon found that the conceptual and technical extensions we needed were quite hard to implement on top of the current version of akka-persistence (2.3.8). We therefore decided for a lightweight re-implementation of the akka-persistence API (with some modifications) together with our extensions for geo-replication. Of course, we are happy to contribute our work back to akka-persistence later, should there be broader interest in our approach.
The extensions we wrote are not only useful in context of geo-replication but can also be used to overcome some of the current limitations in akka-persistence. For example, in akka-persistence, event-sourced actors must be cluster-wide singletons. With our approach, we allow several instances of an event-sourced actor to be updated concurrently on multiple nodes and conflicts (if any) to be detected and resolved. Also, we support event aggregation from several (even globally distributed) producers in a scalable way together with a deterministic replay of these events.
The following sections give an overview of the system model we developed. It is assumed that the reader is already familiar with the basics of event sourcing, CQRS and akka-persistence.
Sites
In our model, a geo-replicated event-sourced application is distributed across sites where each site is operated by a separate data center. For low-latency access, users interact with a site that is geographically close.
Application events generated on one site are asynchronously replicated to other sites so that application state can be reconstructed on all sites from a site-local event log. A site remains available for writes even if it is partitioned from other sites.
Event log
At the system’s core is a globally replicated event log that preserves the happened-before relationship (= potential causal relationship) of events. Happened-before relationships are tracked with vector timestamps. They are generated by one or more vector clocks on each site and stored together with events in the event log. By comparing vector timestamps, one can determine whether any two events have a happened-before relationship or are concurrent.
The partial ordering of events, given by their vector timestamps, is preserved in each site-local copy of the replicated event log: if e1 -> e2 then offset(e1) < offset(e2), where -> is the happened-before relation and offset(e) is the position or index of event e in a site-local event log. For example, if site A writes event e1 that (when replicated) causes an event e2 on site B, then the replication protocol ensures that e1 is always stored before e2 in all site-local event logs. As a direct consequence of that storage order, applications that produce to and consume from the event log experience event replication as reliable, causally ordered event multicast: if emit(e1) -> emit(e2) then all applications on all sites will consume e1 before e2, where -> is the happened-before relation and emit(e) writes event e to the site-local event log.
The relative position of concurrent events in a site-local event log is not defined i.e. concurrent events may have a different ordering in different site-local event logs. Their replay, however, is deterministic per site, as a site-local event log imposes a total ordering on local event copies (which is helpful for debugging purposes, for example). A global total ordering of events is not an option in our case, as it would require global coordination which is in conflict with the availability requirement of partitioned sites. It would furthermore increase write latencies significantly.
In our implementation, we completely separate inter-site event replication from (optional) intra-site event replication. We use intra-site replication only for stronger durability guarantees i.e. for making a site-local event log highly available. We implemented asynchronous inter-site replication independent from concrete event storage backends such as LevelDB, Kafka, Cassandra or whatever. This allows us to replace storage backends more easily whenever needed.
Event-sourced actors
We distinguish two types of actors that interact with the event log: EventsourcedActor and EventsourcedView. They correspond to PersistentActor and PersistentView in akka-persistence, respectively, but with a major difference in event consumption.
Like in akka-persistence, EventsourcedActors (EAs) produce events to the event log (during command processing) and consume events from the event log. A major difference is that EAs do not only consume events they produce themselves but also consume events that other EAs produce to the same event log (which can be customized by filter criteria). In other words, EAs do not only consume events to reconstruct internal state but also to collaborate with each other by exchanging events which is at the heart of event-driven architectures and event collaboration.
From this perspective, a replicated event log is the backbone of a distributed, durable and causality-preserving event bus that also provides the full history of events, so that event consumers can reconstruct application state any time by replaying events. For exchanging events, EAs may be co-located at the same site (Fig. 1) or distributed across sites (Fig. 2)
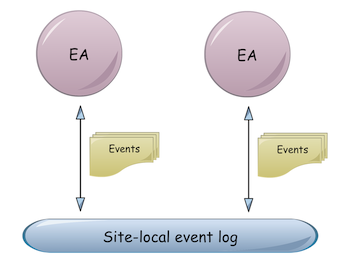
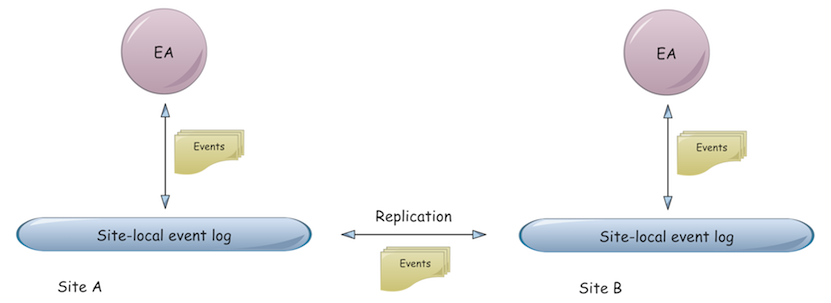
We think that our distributed event bus might be an interesting implementation option of Akka’s event bus, especially for distributed event-based collaboration in an Akka cluster. In this case, Akka cluster applications could also rely on causal ordering of events.
One special mode of collaboration is state replication: EA instances of the same type consume each other’s events to reconstruct application state on different sites (more on that later). A related example is to maintain hot-standby instances of EAs on the same site to achieve fail-over times of milliseconds. Another example of collaboration is a distributed business process: EAs of different type process each other’s events to achieve a common goal. Reliability of the distributed business process is given by durability of events in the event log and event replay in case of failures.
For sending messages to other non-event-sourced actors (external services, …), EAs have several options:
- during command processing with at-most-once message delivery semantics. The same option exists for
PersistentActors in akka-persistence by using a custompersisthandler. - during event processing with at-least-once message delivery semantics. The same option exists for
PersistentActorin akka-persistence by using theAtLeastOnceDeliverytrait. - during event processing with at-most-once message delivery semantics. The same option exists for
PersistentActorin akka-persistence by checking whether a consumed event is a live event or a replayed event.
Replies from external services are processed like external commands: they may produce new events which may trigger the next step in a distributed business process, for example.
Since EAs can consume events from other EAs, they can also generate any view of application state. An EA can consume events from all other globally or locally distributed producers (EAs) by consuming from the shared, replicated event log. This overcomes a current limitation in akka-persistence where events cannot be easily aggregated from several producers (at least not in a scalable and deterministic way).
If an application wants to restrict an actor to only consume from the event log it should implement the EventsourcedView (EV) trait (instead of EventsourcedActor) which implements only the event consumer part of an EA. From a CQRS perspective,
- EAs should be used to implement the command side (C) of CQRS and maintain a write model (in-memory only in our application)
- EVs should be used to implement the query side (Q) of CQRS and maintain a read model (in-memory or persistent in our application)
In addition to EAs and EVs, we also plan to implement an interface to akka-streams for producing to and consuming from the distributed event log.
State replication
As already mentioned, by using a replicated event log, application state can be reconstructed (= replicated) on different sites. During inter-site network partitions, sites must remain available for updates to replicated state. Consequently, conflicting updates may occur which must be detected and resolved later when the partition heals. More precisely, conflicting updates may also occur without an inter-site network partition if updates are concurrent.
An example: site A makes an update to the replicated domain object x1 and the corresponding update event e1 is written to the replicated event log. Some times later, site A receives another update event e2 for the same domain object x1 from site B. If site B has processed event e1 before emitting e2, then e2 causally depends on e1 and site A can simply apply e2 to update x1. In this case, the two updates, represented by e1 and e2, have been applied to the replicated domain object x1 on both sites and both copies of x1 converge to the same value. On the other hand, if site B concurrently made an update to x1 (be it because of a network partition or not), there might be a conflict.
Whether concurrent events are also conflicting events completely depends on application logic. For example, concurrent updates to different domain objects may be acceptable to an application whereas concurrent updates to the same domain object may be considered as conflict and must be resolved. Whether any two events are concurrent or have a happened-before relationship (= potential causal relationship) can be determined by comparing their vector timestamps.
Conflict resolution
If application state can be modeled with commutative replicated data types (CmRDTs) alone, where state update operations are replicated via events, concurrent updates are not an issue at all. However, many state update operations in our application do not commute and we support both interactive and automated conflict resolution strategies.
Conflicting versions of application state are tracked in a concurrent versions tree (where the tree structure is determined by the vector timestamps of contributing events). For any state value of type S and updates of type A, concurrent versions of S can be tracked in a generic way with data type ConcurrentVersions. Concurrent versions can be tracked for different parts of application state independently, such as individual domain objects or even domain object fields, depending on which granularity level an application wants to detect and resolve conflicts.
During interactive conflict resolution, a user selects one of the conflicting versions as the “winner”. This selection is stored as explicit conflict resolution event in the event log so that no further user interaction is needed during later event replays. A possible extension could be an interactive merge of conflicting versions. In this case, the conflict resolution event must contain the merge details so that the merge is reproducible.
Automated conflict resolution applies a custom conflict resolution function to conflicting versions in order to select a winner. A conflict resolution function could also automatically merge conflicting versions but then we are already in the field of convergent replicated data types (CvRDTs).
Comments