DeepSeek-R1 agents with code actions
I ran a quick experiment investigating how DeepSeek-R1 performs on agentic tasks, despite not supporting tool use natively, and I was quite impressed by preliminary results. This experiment runs DeepSeek-R1 in a single-agent setup, where the model not only plans the actions but also formulates the actions as executable Python code. On a subset1 of the GAIA validation split, DeepSeek-R1 outperforms Claude 3.5 Sonnet by 12.5% absolute, from 53.1% to 65.6% correct, and other models by an even larger margin:
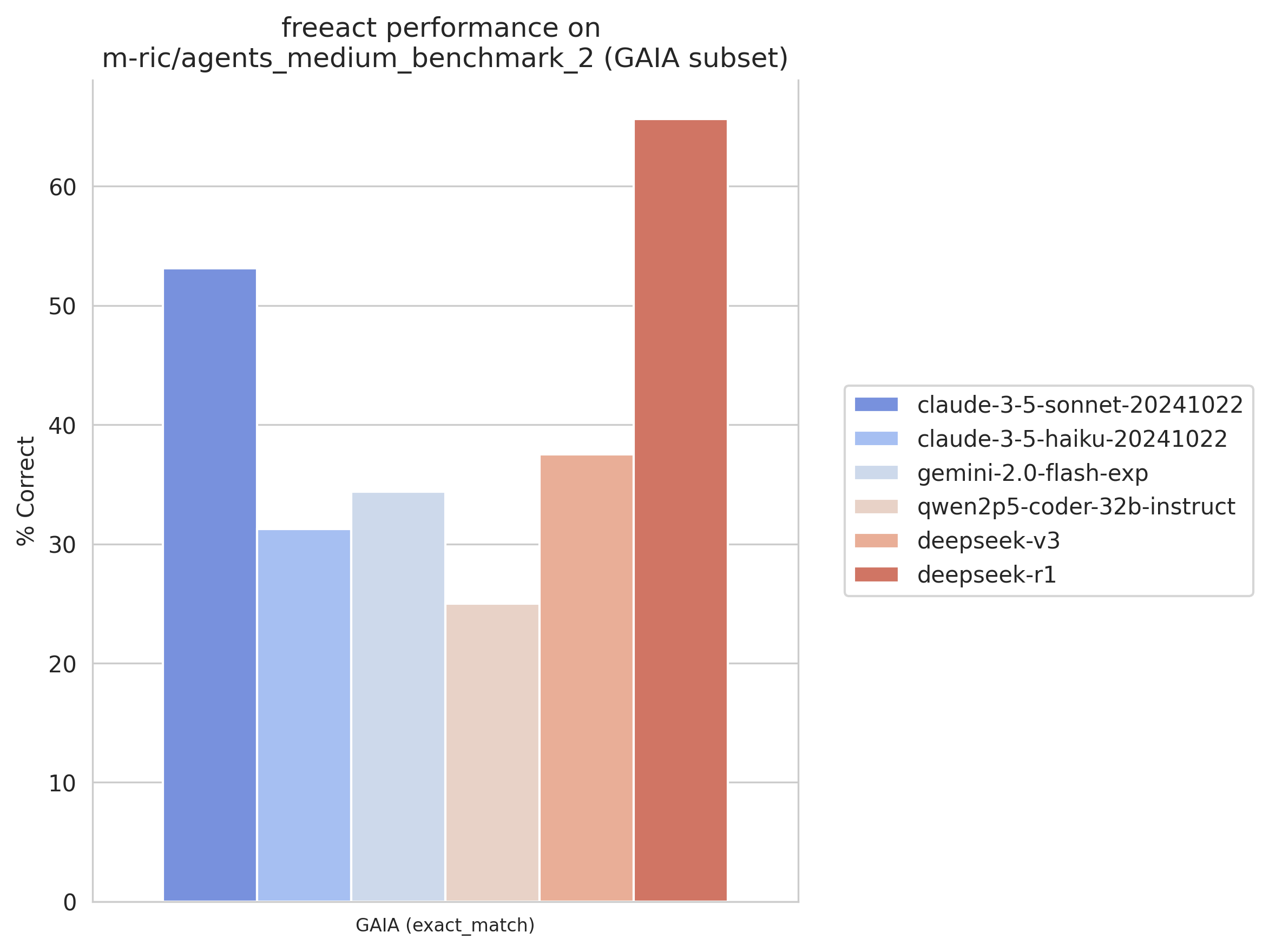
The experiment followed model usage guidelines from the DeepSeek-R1 paper and the model card: Don't use few-shot examples, avoid adding a system prompt, and set the temperature to 0.5 - 0.7 (0.6 was used). You can find further evaluation details here.
Approach
DeepSeek-R1's strong coding capabilities enable it to act as an agent without being explicitly trained for tool use. By allowing the model to generate actions as Python code, it can flexibly interact with environments through code execution.
Tools are implemented as Python code that is included directly in the prompt. This can be a simple function definition or a module of a larger package - any valid Python code. The model then generates code actions that call these tools.
Results from executing these actions feed back to the model as follow-up messages, driving the next steps until a final answer is reached. The agent framework is a simple iterative coding loop that mediates the conversation between the model and its environment.
Conversations
DeepSeek-R1 is used as chat model in my experiment, where the model autonomously pulls additional context from its environment by using tools e.g. by using a search engine or fetching data from web pages. This drives the conversation with the environment that continues until a final answer is reached.
In contrast, o1 models are known to perform poorly when used as chat models i.e. they don't try to pull context during a conversation. According to the linked article, o1 models perform best when they have the full context available, with clear instructions on what to do with it.
Initially, I also tried a full context in a single prompt approach at each step (with results from previous steps included), but this led to significantly lower scores on the GAIA subset. Switching to the conversational approach described above, I was able to reach the reported 65.6% performance.
This raises an interesting question about the claim that o1 isn't a chat model - perhaps this observation was more relevant to older o1 models that lacked tool use capabilities? After all, isn't tool use support an important mechanism for enabling models to pull additional context from their environment? This conversational approach certainly seems effective for DeepSeek-R1, though I still need to conduct similar experiments with o1 models.
Generalization
Although DeepSeek-R1 was mainly trained with RL on math and coding tasks, it is remarkable that generalization to agentic tasks with tool use via code actions works so well. This ability to generalize to agentic tasks reminds of recent research by DeepMind that shows that RL generalizes whereas SFT memorizes, although generalization to tool use wasn't investigated in that work.
Despite its ability to generalize to tool use, DeepSeek-R1 often produces very long reasoning traces at each step, compared to other models in my experiments, limiting the usefulness of this model in a single-agent setup. Even simpler tasks sometimes take a long time to complete. Further RL on agentic tool use, be it via code actions or not, could be one option to improve efficiency.
Underthinking
I also observed the underthinking phenomenon with DeepSeek-R1. This is when a reasoning model frequently switches between different reasoning thoughts without sufficiently exploring promising paths to reach a correct solution. This was a major reason for overly long reasoning traces produced by DeepSeek-R1. This can be seen in the recorded traces that are available for download.
Future experiments
Another common application of reasoning models is to use them for planning only, while using other models for generating code actions. This could be a potential new feature of freeact, if this separation of roles proves useful for more complex tasks.
I'm also curious about how reasoning models that already support tool use (like o1, o3, ...) perform in a single-agent setup, with and without generating code actions. Recent developments like OpenAI's Deep Research or Hugging Face's open-source Deep Research, which also uses code actions, look interesting.
1 The GAIA subset is from this dataset, created by the smolagents team at Hugging Face to evaluate their agents.
Comments