Building an autonomous ML researcher with Claude Code dynamic workflows
This article was originally posted here.
As an experiment, I re-implemented the autonomous ML research-and-engineering workflow encoded in Hugging Face's ml-intern as a Claude Code dynamic workflow that delegates execution to the Hugging Face skills (hf-skills) instead of ml-intern's custom tools1. I did it in three steps: extract a technology-neutral specification of the workflow, compile that specification into a single generic workflow script, then run the script against a concrete task. The result is one workflow that accepts any ML research task as an argument, rather than having Claude Code write a new workflow script for each task.
From ml-intern to a technology-neutral spec
|
I first prompted Claude Code to write a technology-neutral specification of the workflow The spec is a research-first, validate-before-spend, monitor-and-iterate loop with hard rules (persistence, no silent scope changes, sized timeouts, an explicit OOM recovery order) and a control contract (bounded iteration, repetition guards, approval gates). Its central principle: assume internal ML knowledge is stale, so ground every config and import in freshly retrieved literature and working example code rather than writing ML code from memory. |
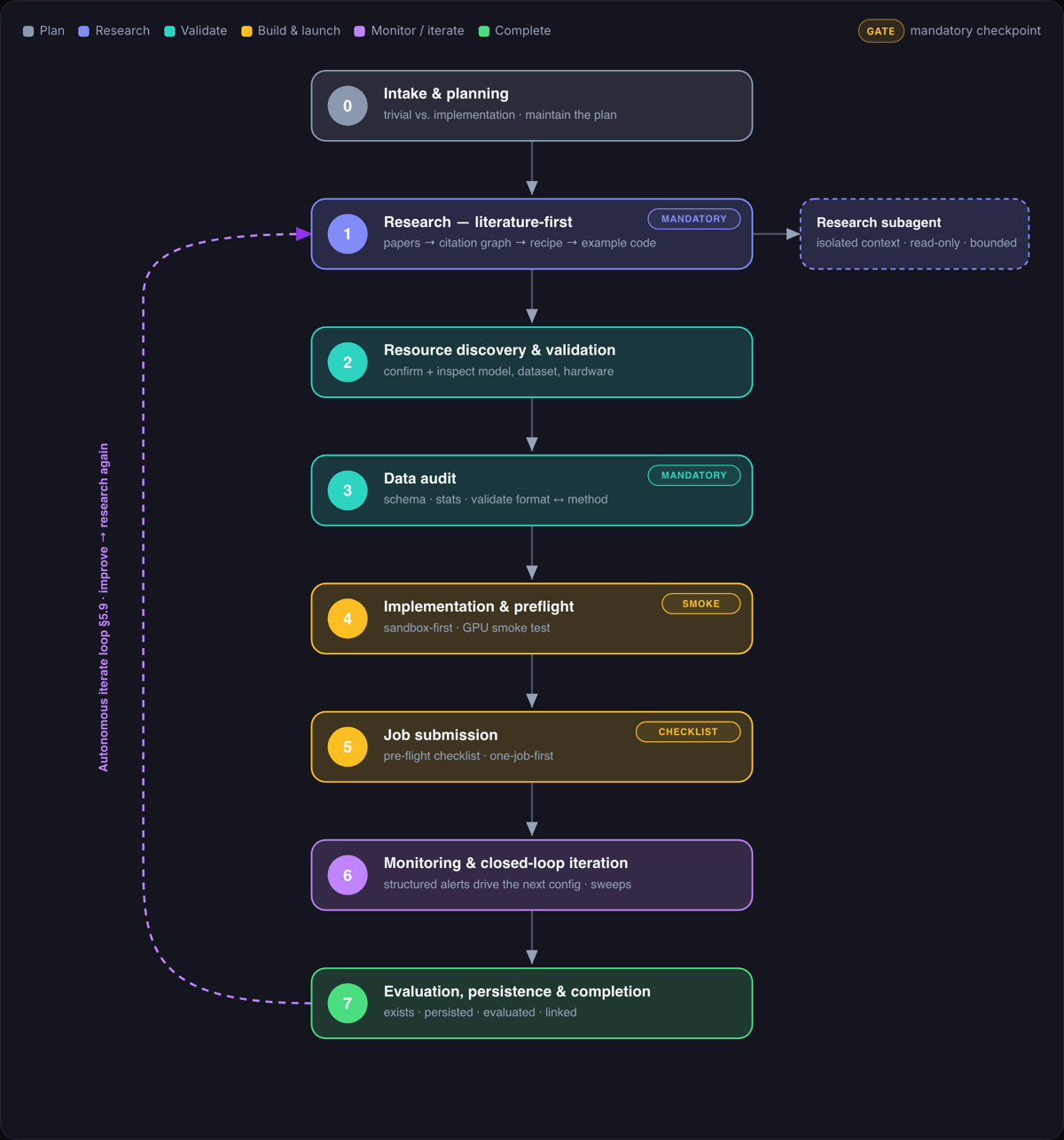
The workflow as specified (interactive version). |
From spec to a generic workflow script
|
I then prompted Claude Code to compile the spec into a generic workflow script invocable with the The result is a 13-phase pipeline where each phase is a subagent that calls the relevant |
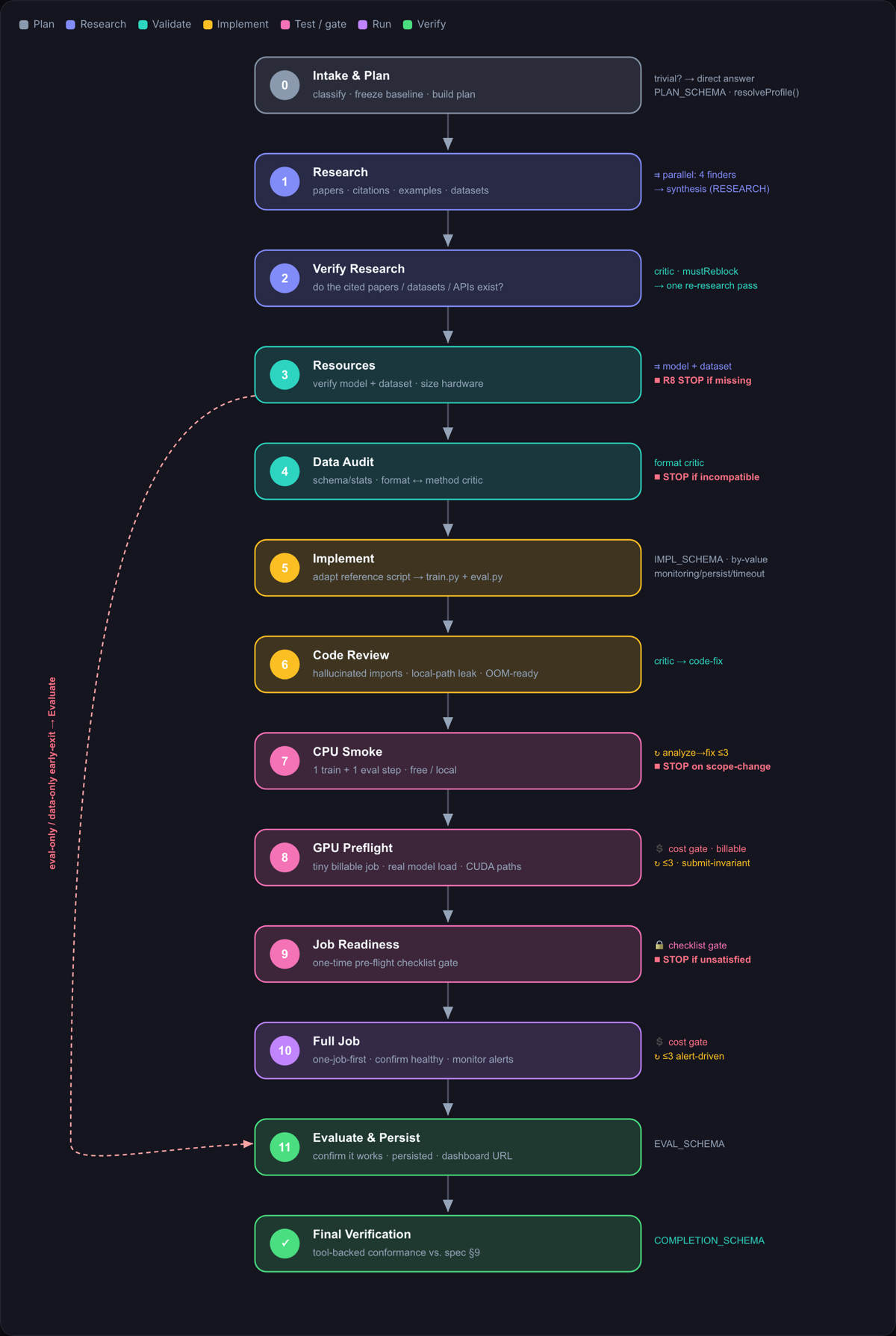
The 13-phase pipeline (interactive version). |
How the spec maps to the script
|
The mapping is close to one-to-one, with a few deliberate differences. The spec's single research phase splits into research plus an adversarial verify. Its implementation-and-preflight phase fans out into implement, code review, a free CPU smoke, and a tiny billable GPU preflight, the script's answer to the spec's acknowledged sandbox gap (no The script also adds explicit gates for job readiness and final conformance, and omits the spec's optional improvement loop at my request, so it stops at the first verified result instead of continuing to chase a better one through hyperparameter sweeps and other refinements (different data, approach, ...). The mapping view labels each correspondence as kept, adapted, added, or omitted. |
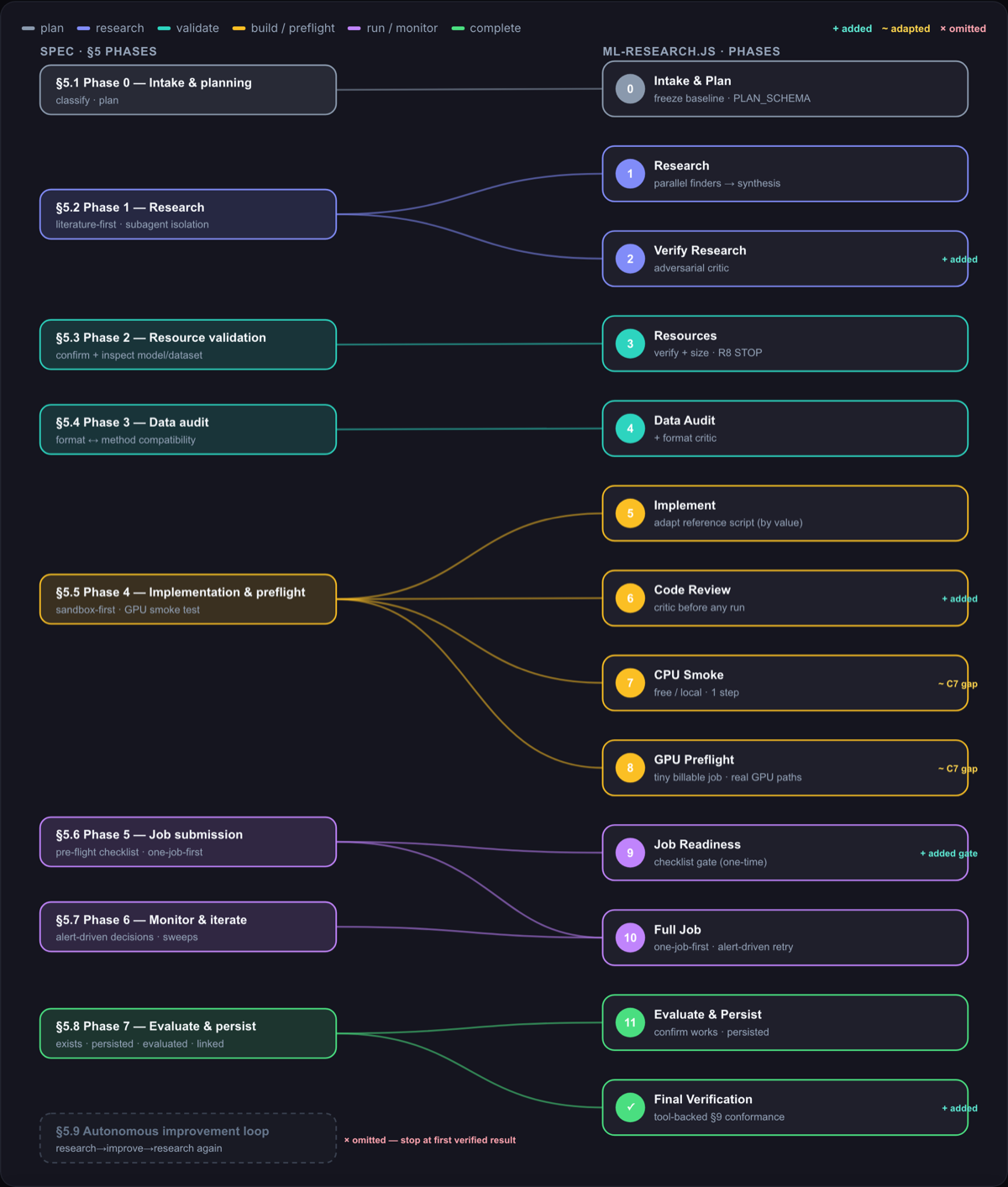
Spec to script mapping (interactive version). |
A first end-to-end run
I invoked the generic script with one line, the task passed as an argument:
/ml-research Fine-tune Qwen/Qwen2-0.5B on trl-lib/Capybara with LoRA on HF Jobs (cost cap is 10 USD)
The run completed on the first attempt and spent 2.14 USD of the 10 USD cap, producing a public LoRA adapter and a Trackio dashboard. The recipe was synthesized from papers the workflow verified actually exist (LoRA r=8 on q_proj,v_proj at lr 1e-4, effective batch 64, cosine schedule, 2 epochs, max_length 2048), grounded in the LoRA and Secret Recipe papers. The full job ran on a single L40S for about 59 minutes with clean monotonic eval loss convergence.
The clearest evidence for the failure-analysis loop appeared during GPU preflight: the workflow hit two non-fatal monitoring bugs (a pyarrow/Trackio serialization crash on the LoRA config, and a double trackio.finish()), diagnosed each from the logs, and fixed them before the full job, which is exactly what the cheap preflight is for: catching these bugs before they waste a paid run.
Conclusion
An autonomous research process, like the one ml-intern implements, can be captured as a technology-neutral spec and compiled into a Claude Code dynamic workflow with two simple prompts. The workflow contributes only discipline (phase ordering, verification gates, persistence and anti-scope-change rules, failure analysis) and stays generic over the task, so a new task is an argument rather than new code. Having Claude Code write task-specific workflow scripts is also possible but was not attempted here. A preliminary conclusion, from a single end-to-end run, is that Claude Code dynamic workflows (currently in research preview) are already a practical path to spec-driven research automation.
1 ml-intern is a self-contained application that ships its own agent loop, tools, and UI. Claude Code already provides that scaffolding and hf-skills wraps the Hugging Face tools (search, datasets, jobs, tracking), so the only part neither provides is the research process definition, which is what the spec captures.
Comments