Using AWS SageMaker with minimal dependencies, part 2
Fault-tolerant model training on spot instances
In a previous article I introduced distributed training with PyTorch Lightning on SageMaker. Training was done with on-demand instances and these can be expected to be available until training completes. The training script therefore did not implement a fault-tolerance mechanism.
Spot instances, on the other hand, can be reclaimed by AWS at any time when more compute capacity is needed. In other words, model training running on spot instances can be interrupted at any time. This behaviour or contract makes spot instances much cheaper than on-demand instances.
To avoid re-training from scratch after an interruption, a training script must be made fault-tolerant. A common approach is to save checkpoints at regular intervals from which training can be resumed when spot capacity becomes available again.
This article demonstrates how to implement this approach for a PyTorch Lightning application by extending the example application from the previous article. The implementation can be easily reused for other applications so that you can reliably train your own models at lower spot instance prices.
Source code and instructions for running the examples are available on Github. Extensions made to the codebase for this article are summarized in this diff.
Spot instance training basics
When a spot instance is reclaimed by AWS during a training job, SageMaker interrupts training i.e. kills all training processes and restarts training when sufficient spot capacity becomes available again (see managed spot training for details). During restart, a training script has the option to resume from a previously saved checkpoint.
A common choice is to save checkpoints every epoch. When writing these checkpoints to a SageMaker-specific local
checkpoint directory (/opt/ml/checkpoints by default), SageMaker automatically copies these checkpoints to a
user-defined S3 location. When training is restarted, SageMaker copies the checkpoint back to the local checkpoint
directory so that it can be loaded by the training script.
Training script extensions
In the previous article, the training script
wrote checkpoints to a SageMaker-specific output directory defined by the SM_OUTPUT_DATA_DIR environment variable.
Content of this directory is copied to S3 when training completes (successfully or not) but is not copied back when
training is restarted. Also, checkpoints have only been written when the validation loss improved over a previously
saved checkpoint.
For checkpointing every epoch and synchronizing checkpoints with S3 in both directions the following extensions are
needed. To additionally write a last.ckpt every epoch, the model checkpoint callback in trainer.yaml
is configured with save_last: true.
#
# File: app/trainer.yaml
#
trainer:
callbacks:
- class_path: pytorch_lightning.callbacks.model_checkpoint.ModelCheckpoint
init_args:
...
save_last: true
...
...
To write checkpoints to a SageMaker-specific local checkpoint directory, the training script sets the checkpoint
callback's dirpath to a directory defined by environment variable SM_CHECKPOINT_DIR.
#
# File: app/train.py
#
import os
from pytorch_lightning.utilities.cli import LightningCLI
logger = ...
class CLI(LightningCLI):
def __init__(self, *args, **kwargs):
self.sm_checkpoint_dir = os.environ.get("SM_CHECKPOINT_DIR")
...
super().__init__(*args, **kwargs)
@property
def last_checkpoint_path(self):
if self.sm_checkpoint_dir:
return os.path.join(self.sm_checkpoint_dir, 'last.ckpt')
@property
def model_checkpoint_config(self):
for callback_config in self.config["trainer"]["callbacks"]:
class_path = callback_config.get("class_path")
if "ModelCheckpoint" in class_path:
return callback_config
def before_instantiate_classes(self) -> None:
if self.sm_checkpoint_dir:
logger.info(f'Update checkpoint callback to write to {self.sm_checkpoint_dir}')
self.model_checkpoint_config['init_args']['dirpath'] = self.sm_checkpoint_dir
...
When training is restarted, SageMaker copies previously saved checkpoints to the local checkpoint directory so that
they can be loaded by the training script. When a last.ckpt file exists in the checkpoint directory, training is
resumed from this checkpoint, otherwise, training is started from scratch.
def main():
cli = CLI(...) # instantiate trainer, model and data module
if cli.last_checkpoint_path and os.path.exists(cli.last_checkpoint_path):
logger.info(f'Resume training from checkpoint {cli.last_checkpoint_path}')
cli.trainer.fit(cli.model, cli.datamodule, ckpt_path=cli.last_checkpoint_path)
else:
logger.info('Start training from scratch')
cli.trainer.fit(cli.model, cli.datamodule)
Spot instance training
Running spot instance training is straightforward with the Estimator API of the SageMaker Python SDK.
Compared to on-demand training, spot instance training additionally requires setting
use_spot_instances=True.max_retry_attempts=nwherenis the maximum number of times training is restarted.max_wait=t1wheret1is the maximum number of seconds to wait for training to complete and, if needed, for spot instance capacity to become available.max_run=t2wheret2is the maximum number of seconds to wait for training to complete (must be less thant1).checkpoint_s3_uri=ckpt_uriwhereckpt_uriis a user-defined S3 location for synchronizing checkpoints with the local checkpoint directory.checkpoint_local_path=ckpt_pathwhereckpt_pathis the local checkpoint directory (/opt/ml/checkpointsby default).
In the following code template, set account_id, region, role_name and my_bucket to appropriate values for your
AWS environment:
from datetime import datetime
from sagemaker import Session
from sagemaker.estimator import Estimator
SM_CHECKPOINT_DIR = "/opt/ml/checkpoints"
# Set according to your AWS environment
account_id = ...
region = ...
role_name = ...
my_bucket = ...
timestamp = datetime.now().strftime("%Y-%m-%d-%H-%M-%S")
job_name = f"sagemaker-tutorial-{timestamp}"
session = Session()
estimator = Estimator(image_uri=f"{account_id}.dkr.ecr.{region}.amazonaws.com/sagemaker-tutorial:latest",
role=f"arn:aws:iam:<account-id>::role/{role_name}",
instance_type="ml.g4dn.12xlarge",
instance_count=2,
output_path=f"s3://{my_bucket}/output",
checkpoint_s3_uri=f"s3://{my_bucket}/output/{job_name}/checkpoints",
checkpoint_local_path=SM_CHECKPOINT_DIR,
use_spot_instances=True,
max_retry_attempts=3,
max_wait=14400,
max_run=3600,
sagemaker_session=session,
environment={
"SM_CHECKPOINT_DIR": SM_CHECKPOINT_DIR
},
hyperparameters={
"data": "CIFAR10DataModule",
"data.batch_size": 32,
"optimizer": "Adam",
"optimizer.lr": 1e-3,
"trainer.accelerator": "gpu",
"trainer.devices": -1,
"trainer.max_epochs": 5,
"logger.save_dir": f"s3://{my_bucket}/output/{job_name}/logger-output",
"logger.flush_secs": 5,
"logger.name": "tutorial"
})
estimator.fit(inputs=f"s3://{my_bucket}/datasets/cifar-10", job_name=job_name)
This code snippet also sets the environment variable SM_CHECKPOINT_DIR which is then passed to the training script.
I actually expected this to be set by the SageMaker training toolkit
but this is not the case. To preserve symmetry with other SageMaker-specific local paths and their corresponding
environment variables I decided to introduce this variable here.
Simulating training interruption
Since SageMaker doesn't expose the IDs of its managed spot instances, we cannot use Amazon's fault injection simulator to interrupt them. Instead, we'll run training for 5 epochs and then resume training to run for further 2 epochs. Both training runs share their S3 checkpoint location. Training is started as in the previous section except that the S3 checkpoint location doesn't contain a job name.
estimator = Estimator(..., checkpoint_s3_uri=f"s3://{my_bucket}/checkpoints")
estimator.fit(...)
To train for further 2 epochs, training is started again with trainer.max_epochs=7. Since the S3 checkpoint location
is reused, SageMaker copies last.ckpt to the local checkpoint directory from where it is loaded by the training script.
estimator = Estimator(...,
checkpoint_s3_uri=f"s3://{my_bucket}/checkpoints",
hyperparameters={..., "trainer.max_epochs": 7, ...})
estimator.fit(...)
Tensorboard can be used to visualize how the second training run (blue) resumed from where the first (orange) stopped.
The following traces are from a training run on 2 ml.g4dn.xlarge instances (with only 1 GPU per instance, for testing
purposes).
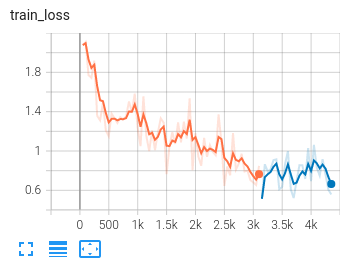
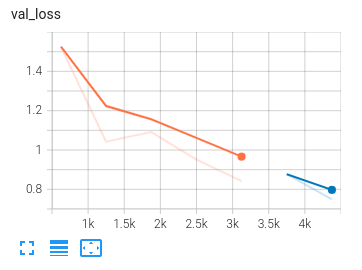
Conclusion
Making a training script fault-tolerant for managed spot instance training is as simple as writing checkpoints to a SageMaker-specific local checkpoint directory and loading the most recent checkpoint when training is restarted. Restarting training on spot instance interruption and synchronizing checkpoints with S3 is handled by SageMaker automatically and doesn't require any extensions to the training script. Managed spot instance training allows you to train your PyTorch (Lightning) models reliably at lower spot instance prices, even in a multi-node, multi-GPU environment.
Acknowledgements
Many thanks to Christoph Stumpf for useful feedback on this article and associated code, and Bernadette Hainzl for the wonderful painting in the header section.
Comments