Extending Visual ChatGPT with image search engines
The source code for this article, an extended version of Visual ChatGPT, is available here. Update: A 🤗 Transformers Agent based implementation of the examples in this article is available here.
A recent trend in software development uses large language models (LLMs) to understand user input in natural language and to execute complex user instructions by autonomously decomposing them into simpler subtasks. These LLMs are often augmented with application-specific reasoning skills and the ability to use external tools [1]. LLM augmentation requires learning, either in-context learning (prompting) or fine-tuning. External tools help LLMs to execute specialized tasks for which the model itself doesn't have sufficient capabilities. This can be, for example, an external knowledge source for retrieving factual and up-to-date information, or a calculator for answering more complex math questions.
Visual ChatGPT
A good example of an augmented LLM is Visual ChatGPT [2]. It enables users to interact with ChatGPT not only via text but also images. For image processing and generation it integrates visual foundation models (VFMs) as external tools. The language model learns usage of VFMs and handling of image data via prompting. Prompts are managed by a central component, the Prompt Manager, which also mediates information exchange between ChatGPT and VFMs:
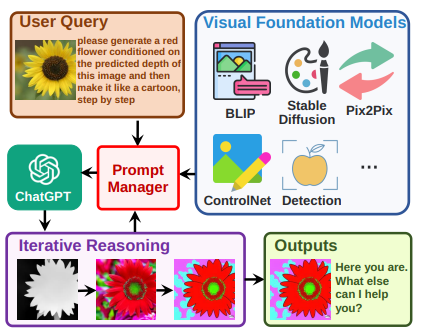
For implementing the Prompt Manager, Visual ChatGPT uses LangChain, a framework for developing applications powered by language models. LangChain connects language models to other sources of data and allows them to interact with their environment. It enables language models to behave like agents, making decisions about which actions to take, taking that action, seeing an observation, and repeating that until done.
Visual ChatGPT with image search
A current limitation of Visual ChatGPT (at the time of writing this article) is that it does not support image search.
This section demonstrates how to implement tools for image search, both by query text and query image. For simplicity,
these tools only return the top-scoring image in order to make them compatible with the current Visual ChatGPT user
interface. The search tools use the clip-retrieval client for searching
images in the LAION-5B dataset [3]. The client is instantiated in a SearchSupport base class:
from clip_retrieval.clip_client import ClipClient, Modality
class SearchSupport:
def __init__(self):
self.client = ClipClient(
url="https://knn.laion.ai/knn-service",
indice_name="laion5B-L-14",
modality=Modality.IMAGE,
num_images=10,
)
ClipClient can be used for both, image search by query text (self.client.query(text=...)) and query image
(self.client.query(image=...)). The only thing required for integrating image search as external tool into Visual
ChatGPT, is to describe the behavior of the search tool in plain English with a @prompts decorator, and implementing
an inference method for interacting with the search engine. ImageSearch implements search by query text:
from search import download_best_available
from utils import get_image_name, prompts
class ImageSearch(SearchSupport):
@prompts(name="Search Image That Matches User Input Text",
description="useful when you want to search an image that matches a given description. "
"like: find an image that contains certain objects with certain properties, "
"or refine a previous search with additional criteria. "
"The input to this tool should be a string, representing the description. ")
def inference(self, query_text):
search_result = self.client.query(text=query_text)
return download_best_available(search_result, get_image_name())
The values of the name and description parameters of the @prompts decorator take into account the prompt management
aspects described in section 3.2 of [2] (Prompt Managing of Foundation Models). These are included as-is into the
language model prompt (among many other details) so that ChatGPT learns about the existence of the search tool, the
conditions when it should be selected, some abstract usage examples and the expected input type.
A search_result object contains the URLs of the top 10 images and download_best_available downloads the top scoring
image from the internet, if available, otherwise the next best scoring image (recursively). The downloaded image is stored
under a unique filename generated by get_image_name().
VisualSearch searches an image that is visually similar to a query image. The implementation closely follows
that of ImageSearch. The major difference is the tool description in the @prompts decorator, of course. The filename
generated by get_new_image_name is a chained filename, for reasons explained in section 3.4 of [2] (Prompt Managing
of Foundation Model Outputs).
from search import download_best_available
from utils import get_new_image_name, prompts
class VisualSearch(SearchSupport):
@prompts(name="Search Image Visually Similar to an Input Image",
description="useful when you want to search an image that is visually similar to an input image. "
"like: find an image visually similar to a generated or modified image. "
"The input to this tool should be a string, representing the input image path. ")
def inference(self, query_img_path):
search_result = self.client.query(image=query_img_path)
return download_best_available(search_result, get_new_image_name(query_img_path, "visual-search"))
Importing ImageSearch and VisualSearch into visual_chatgpt.py
is sufficient for being able to load these search tools from the command line.
Application setup
Set up a virtual environment as described in Quick Start and then start the application with
python visual_chatgpt.py \
--load="ImageCaptioning_cuda:0,ImageEditing_cuda:1,Text2Image_cuda:2,ImageSearch_,VisualSearch_" \
--port=6010
This loads three VFMs and the two search tools. The following examples have been generated with this
configuration. You may need to adjust the device settings (cuda:0, cuda:1, ...) depending on the number and size of
available GPUs.
Usage examples
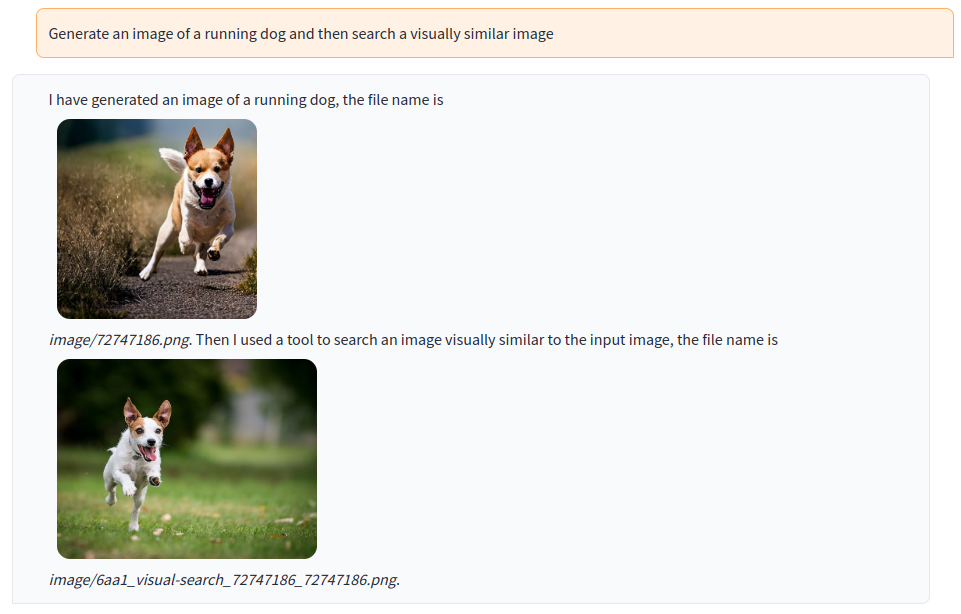
Generate an image and find a visually similar image in the LAION-5B dataset. The generated image is used as query image:
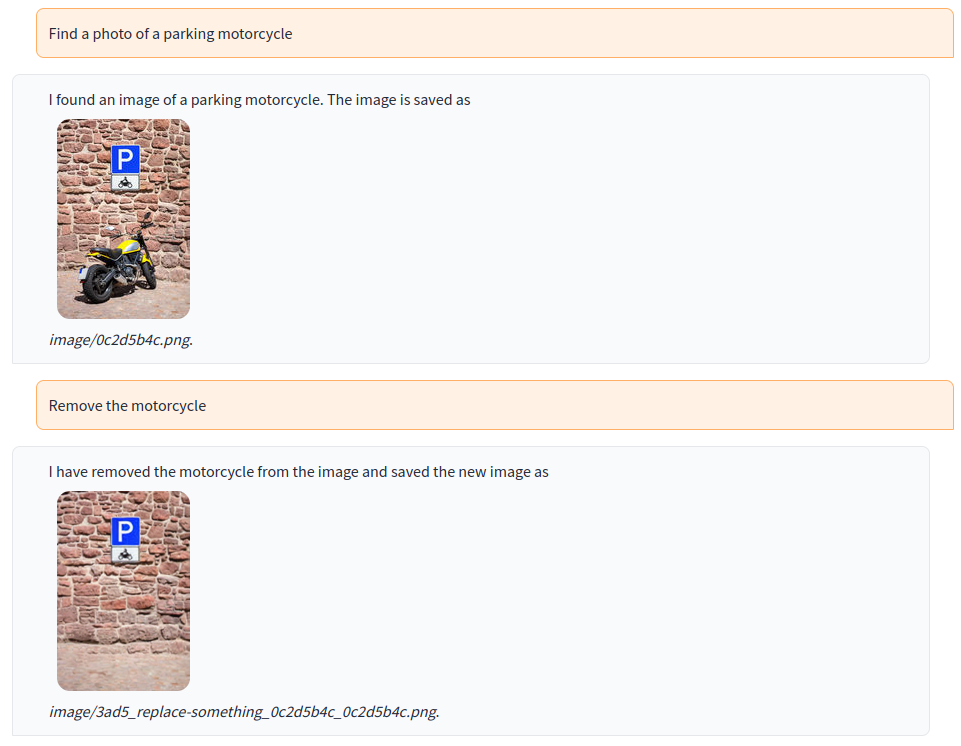
Search an image in the LAION-5B dataset matching a user-provided description (query text) and then process that image with a visual foundation model:
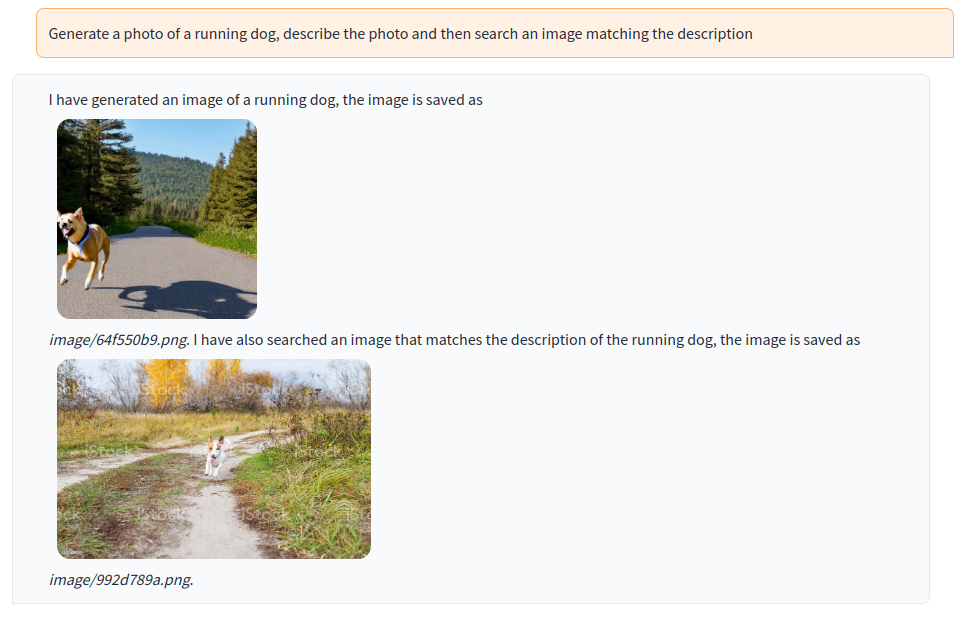
Instruct Visual ChatGPT to generate an image, caption that image and then search for a LAION-5B image matching the caption. The instruction is decomposed by ChatGPT into three steps: image generation, image captioning and image search by query text:
These are rather simple examples. You can of course combine the search tools with other VFMs to support more complex image processing and search workflows.
References
[1] G. Mialon, R. Dessì, M. Lomeli, C. Nalmpantis, R. Pasunuru, R. Raileanu, B. Rozière, T. Schick, J. Dwivedi-Yu, A. Celikyilmaz, E. Grave, Y. LeCun, and T. Scialom. Augmented Language Models: A Survey. arXiv preprint arXiv:2302.07842, 2023.
[2] Chenfei Wu, Shengming Yin, Weizhen Qi, Xiaodong Wang, Zecheng Tang, and Nan Duan. Visual chatgpt: Talking, drawing and editing with visual foundation models. arXiv preprint arXiv:2303.04671, 2023.
[3] Schuhmann, C., Beaumont, R., Vencu, R., Gordon, C., Wightman, R., Cherti, M., Coombes, T., Katta, A., Mullis, C., Wortsman, M., et al. LAION-5B: An open large-scale dataset for training next generation image-text models. arXiv preprint arXiv:2210.08402, 2022.
Comments